wickedliving
-
Posts
12 -
Joined
-
Last visited
-
Hello everyone, I'm back!! I have been working on a project that involves DayZ (standalone). I am trying to implement private hives as my end goal. I am struggling with an sqlite blob of data that they dump into the db and when the player reenters the game, it parses the blob for use. I'm mostly struggling because the data seems all over the place. I've figured out some good chunks of the data but I'm struggling with about 170-175 bytes that I'm positive are used for player stats. Generally, the blob is pretty straightforward. The blob is pasted below for reference. The first 16 bytes are position data. 02 00 79 D4 4B 46 CC 13 B8 40 9E FF F4 45 22 7C The first two bytes, 02 00, are unknown but I believe it has something to do with rotational value. The next four bytes, 79 D4 4B 46, are position X and create little endian float32 value of 13045.1 The next four bytes, CC 13 B8 40, are unknown, but again I'm pretty sure it is a LE float32 with a value of 5.75242 (I think a rotation) The next four bytes, 9E FF F4 45, are position Y and create LE float32 value of 7839.95. The next four bytes, 22 7C 0F 53, are unknown but create a LE float32 value of 6.16263E+11 This is where things get similar to Conquer string packing. The next byte, 0F, is a uint8 equal to 15. The next 15 bytes provide the model name in ascii: SurvivorF_Linda (53 75 72 76 69 76 6F 72 46 5F 4C 69 6E 64 61) The next 12 bytes, 03 01 00 00 5A 00 00 00 00 00 05 00, are not prefixed by any leading byte designating the length. I am guessing this determines the model options when setting up your character but I have no verified it. I'm not worried about this portion yet. The next series of bytes provide overall stats and are prefixed by a length designator. Immediately following the length prefix are 4 bytes which contain the value for the stat which vary from float32 to int32. 04 64 69 73 74 06 58 7F 40 [4] [dist] [3.98975] (float32) 0E 70 6C 61 79 65 72 73 5F 6B 69 6C 6C 65 64 00 00 00 00 [14] [players_killed] [0] (int32) 0F 69 6E 66 65 63 74 65 64 5F 6B 69 6C 6C 65 64 00 00 00 00 [14] [infected_killed] [0] (int32) 08 70 6C 61 79 74 69 6D 65 08 EC 22 43 [8] [playtime] [162.922] (float32) 14 6C 6F 6E 67 65 73 74 5F 73 75 72 76 69 76 6F 72 5F 68 69 74 00 00 00 00 [14] [longest_survivor_hit] [0] (flaot32) Most of this so far has been a write up, but I really am struggling with this next part. Currently, I'm sifting through Ghidra and ImHex of a memory dump to try to figure out how the next 170-175 bytes are created. After the 170-175 bytes the items begin which is pretty straightforward because they are length prefixed, strings, and that stats for the items are straightforward too. I am very much struggling with these 170-175 bytes though. I have gone in the game and tried performing different things to get the values to change, but it all seems random. Any help would be appreciated, even if you take a quick look and notice a pattern within the series. Full blob dump:
-
Comet's is probably the most documented and easiest to understand. Although, I have only ever used his source as reference. I've also used CptSky's source for reference. A lot of the sources floating around are not good reference material. They're semi-stable sources that people then use to create spaghetti monsters with and "release" them. However, this is a lot better of a community than where those releases are. If you somewhat know how to program, and you look at source and cannot figure out at least *what* the code is doing, it's probably a source you shouldn't be using for material. There's also Spirited's Wiki
-
Thanks for the feedback! I did some research and I don't think Go has jump tables for switch statements as of now, unless I was reading the GitHub issue wrong. I also found this: https://hashrocket.com/blog/posts/switch-vs-map-which-is-the-better-way-to-branch-in-go but it also states maps are slower until larger sets. I have not benchmarked it yet, but eventually I will get around to it. One issue I have found with using this approach, it that when you hit MsgAction, you start requiring sub-routes or rather lengthy switch statements. I'd be interested to hear some feedback from the community on other ways to approach this in a clean and also performant way!
-
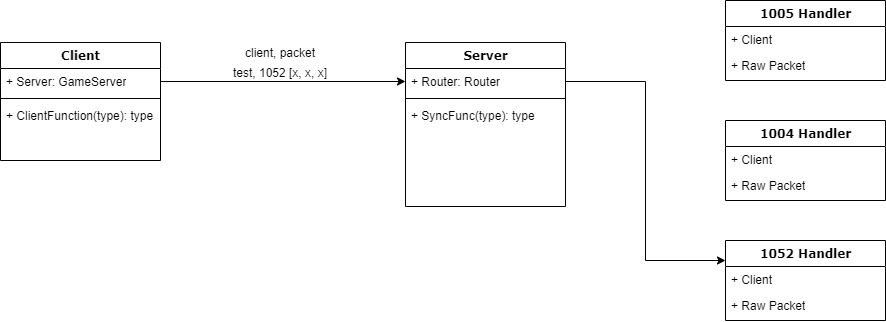
Upon initially developing my conquer server from scratch, I was not a fan of how people were using lengthy switch statements. I took a traditional Go approach and developed a Routing service for incoming client -> server messages. If you have ever worked with Go http handlers, you probably already know what I am referring to. The approach is having a predefined list (map) of all available routes and handlers. In my opinion, this makes for cleaner sources and (albeit minor) more time efficient packet handling. When the server receives, it routes the raw messages based on the packet type (ie [1001]) to the associated handler function along with the client that sent it. I've excluded what happens from there, as the rest is based off how your server handles synchronizing the game state. Essentially, the use of it would look like this: server.Router = router.NewRouter() s.Router.Add(router.NewRoute().Name(msg.MsgConnectType).Process(MsgConnectProcess)) You could organize these routes by type or by their functionality. When looking for a specific handler, instead of digging through files (or worse, a switch statement) you could go to where your router is located and find which handler belongs to the route. I've attached the router below (Go), but this could be ported if desired. If you find any bugs, please let me know! // Router uses a map to find processes in constant time, if the router // cannot find the specified Route, it send it to the DefaultRouteProcess type Router struct { routes map[uint16]*Route NotFoundProcess Process } // NewRouter creates a router, instantiates a map, and returns a pointer // to the router func NewRouter() *Router { return &Router{ routes: make(map[uint16]*Route), } } // Add makes a new entry into the Router's map, the name of the route // will always be the map location of the route. func (r *Router) Add(route *Route) { r.routes[route.name] = route } // Process looks up the Route by name, which is supplied by the first // 2 bytes of the slice, as a uint16. If the process is located, it // sends off the client and byte slice to the designated process. func (r *Router) Process(client interface{}, h *packet.Header) { if route, ok := r.routes[h.Type]; ok { if route.process == nil { log.Warn(fmt.Sprintf("No process given for %d\n", h.Type)) return } route.process(client, h) return } if r.NotFoundProcess != nil { r.NotFoundProcess(client, h) return } r.defaultNotFoundProcess(client, h) } func (r *Router) defaultNotFoundProcess(_ interface{}, h *packet.Header) { log.Warn(fmt.Sprintf("[Mux] Packet [%d] not implemented!\n", h.Type)) } // Route is how the router determines what process to run for the given // client and slice. type Route struct { name uint16 process Process } // NewRoute creates a new route, and returns a pointer to that route, // To add a name and process, it is recommended to use Name() and Process() func NewRoute() *Route { route := new(Route) return route } // Name adds a name to the receiver route func (r *Route) Name(name uint16) *Route { r.name = name return r } // Process adds a process to the receiver route func (r *Route) Process(f Process) *Route { r.process = f return r } // Process defines the function allowed to be used as a Process. // interface is used as a holder for Client, and a byte slice for passing raw message. type Process func(interface{}, *packet.Header)

-
That's awesome! I don't have anything to actually do this on, but it's interesting!
-
Okay, I see what you mean. I am not sure about 5187, but I'm pretty sure all clients that use RC5 use the same seed which is the byte array you provided earlier. The way I understand COP's RC5 library (using my very limited memory of C#), it's initialized using that seed. { 0x3C, 0xDC, 0xFE, 0xE8, 0xC4, 0x54, 0xD6, 0x7E, 0x16, 0xA6, 0xF8, 0x1A, 0xE8, 0xD0, 0x38, 0xBE } Other than the comments, that isn't provided anywhere in his library. That has to be provided by you when using RC5. The link I've posted below shows where in his source he is using it. https://gitlab.com/conquer-online/servers/cops-v6-emulator-enhanced-edition/-/blob/master/AccServer/Network/MsgAccount.cs#L56
-
I'm a little confused on what you're asking. Are you attempting to rewrite/port CptSky's RC5 version or just understand it more?
-
I was able to reduce the size pretty significantly by removing the unnecessary fields, including the extra Vectors that were already being used as the keys. I may actually create some sort of option flags for this dmap system since it will almost certainly be used in my stress test bot as well. I'm using this for more of a validation for player movements, item placement, and mob movements. My project structure is a little different than other servers as I'm not taking the traditional map route. I've actually created my server around Zones, and each zone has a conquer map assigned to it. For instance, Twin City map id is 1002, but it's zone ID is 1. If I wanted to duplicate Twin City for single player instances (like GW1) I can do that. I plan on using this feature mostly for quests and guild/team instances. So my map system has to be reusable and completely separate from zones. I'm using the map points as a reference to make sure that whatever a player (or the server) is attempting to do is also valid with the client. Everything else, such as items on ground or mobs walking, is based on the zone and the entities inside of it. Kind of off topic, but gives you an idea of why memory matters to me. I really appreciate everyones help! Hopefully one day it's in a stable enough condition for me to release it.
-
I can't imagine the map sizes of the MMORPG's like GW2 and WoW. I thought about doing a Map struct and breaking it to quadrants like you said. I've managed to make it around 65mb for canyon by ridding myself of the surface type and making my Vector2 coords uint16 instead of uint32. Here are my current structs type DMap struct { Id int xMax uint32 yMax uint32 Tiles map[Vector2]Tile } type Tile struct { Vector2 Valid bool Height byte } type Vector2 struct { X uint16 Y uint16 }
-
Hey everyone, I'm looking for better alternatives (to save memory) for validating map coordinates. Currently, I load every dmap with xMax and yMax with a map[Vector2]Tile This means I can lookup points using the the coordinates and the the valid, surface, and height of each tile. This approach requires 100mb for Canyon alone, which I'm attempting to reduce it. Any and all help would be appreciated!
-
For future reference of anyone struggling with the same question, CptSky's CO2_CORE_DLL's COCAC is the answer.
-
Hello, I'm currently working on a couple tools for my server I have been developing over the last few months. One of these tools is a stress test bot that I can't quite figure out the authentication part. My servers encryption works great, but what isn't working is the bot's initial encryption. I believe it has something to do with usually being used to decrypt first, before encrypting. func (c *Xor) Encrypt(dst, src []byte) { for i, v := range src { dst[i] = v ^ 0xAB dst[i] = dst[i]>>4 | dst[i]<<4 dst[i] = dst[i] ^ c.dKey[byte(c.encrypt&0xff)] dst[i] = dst[i] ^ c.dKey[(c.encrypt>>8)+0x100] c.encrypt++ } } So my question is if there is a separate key being used for the client sending message 1051?